
Recently I was building a solution for managing some contents. I used a document oriented database for storing the actual contents. In this particular scenario, I used CouchDB. First a POC was built, just to get an idea of the domain and what was possible to achieve, given a fixed amount of resources. Then the actual product work began. One requirement was to be able to reuse content. The reuse strategy picked was, by faking references. So there was no duplication and embedding of data, instead, there was a referencing solution. This post is about the shortcomings that I’ve found with going that route.
First model
The model has been renamed and I have removed all the unimportant attributes, just so that we can focus on the relations (in a non relational world).
There’s a Master, keeping track of the structure, that is it has no direct content, only meta-data and information about what should be included. There’s a tree structure, where Master has many Sections and each section has two collections of content. Again, names are fakes, given this info, we have something like this:
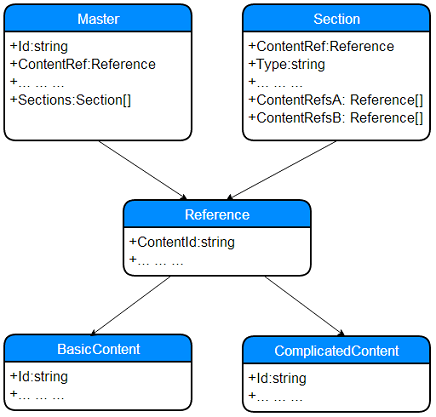
So, Master has a reference to a content; each Section has one for it self and one for every item in it’s arrays of content references: ContentRefA and ContentRefB.
Consuming the first model
To get one “actual”, fully populated Master, first the meta needs to be pulled, then all its ReferenceIds need to be extracted and then all contents for these needs to be queried. At least, all the contents, despite being different: BasicContent vs CompicatedContent; can be fetched at the same time from CouchDB, by emitting a key that indicates what kind of document it is, that we can use to separate the different streams and thereby deserialize the JSON correctly.
In total, two requests for one document: one by key and one query against a secondary index to get the actual contents. For performance reasons, the assembled entity would be cached.
Final solution
The initial solution introduced to much accidental complexity into the application layer. A more document oriented approach was selected instead; where everything was kept in one document, by embedding the content in the Master.

This redesign, did not only reduce the amount of code, it also reduced the total number of documents by more than 90% and reduced the number of requests and removing the need of secondary indexes in CouchDB.
Even though the requirement with reuse was scratched, it could still be satisfied by duplicating content (think copy paste into real documents). Doing that would how-ever, introduce some more complexity into the application layer again. E.g. since ACID within CouchDB, only goes for one document, not across documents. How-ever, there are some document databases that do. E.g. RavenDB and Microsoft’s cloud based DocumentDB.
Summary
A document is a really good analogy to the real world. A reference is like a footnote, and walking that reference, could be seen as a person walking to fetch the referenced document in another archive. Now, some persons will walk faster than other (SSD vs HDD). Some will be closer to the archive (sharding). Some will have a very good categorization (index) and some will have the document already lying on the desk (cache). The point is, it will cost you more. Not talking about space. More network traffic and accidental complexity in your application.
Know your tool and its limitations.
//Daniel