
Time for a quick look at UTF-8 encoding and byte order marker (BOM). Lets jump right into some code. You are probably going to nail this as you most likely will be alert now, given the title and all, but would you have expected this test to pass?
[Fact]
public void Utf8Strings()
{
var initial = "Hello world!";
using var ms = new MemoryStream();
using var writer = new StreamWriter(ms, Encoding.UTF8);
writer.Write(initial);
writer.Flush();
Assert.Equal(
initial,
Encoding.UTF8.GetString(ms.ToArray()));
}
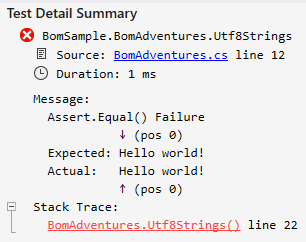
So, what is happening here? Lets take a look at a second test to make it a bit more clear.
[Fact]
public void Utf8Arrays()
{
var initial = "Hello world!";
using var ms = new MemoryStream();
using var writer = new StreamWriter(ms, Encoding.UTF8);
writer.Write(initial);
writer.Flush();
Assert.Equal(
Encoding.UTF8.GetBytes(initial),
ms.ToArray());
}
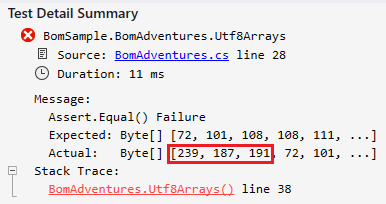
What are those extra bytes?
It's the byte order marker (BOM) and when it comes to UTF-8, it's essentially indicating that the stream consists of UTF-8 encoded bytes. It can also be used to tell if the byte order is in little- or big-endian order. Here's a good place to read about it in a somewhat understandable way: https://www.unicode.org/faq/utf_bom.html#bom1
Here are some extracted parts from Unicode.Org's FAQ:
Q: What does ‘endian’ mean?
A: Data types longer than a byte can be stored in computer memory with the most significant byte (MSB) first or last. The former is called big-endian, the latter little-endian...
(https://www.unicode.org/faq/utf_bom.html#bom3)
Q: Can a UTF-8 data stream contain the BOM character (in UTF-8 form)?
Yes, UTF-8 can contain a BOM. However, it makes no difference as to the endianness of the byte stream. UTF-8 always has the same byte order...
(https://www.unicode.org/faq/utf_bom.html#bom5)
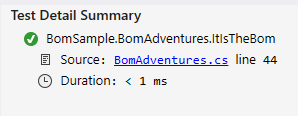
Can we find the BOM for UTF-8 in .NET?
Yes. It's located in the Encoding.Preamble or Encoding.GetPreamble():
[Fact]
public void ItIsTheBom()
{
Assert.Equal(
new[] { 0xEF, 0xBB, 0xBF },
new[] { 239, 187, 191 });
Assert.Equal(
new byte[] { 239, 187, 191 },
Encoding.UTF8.GetPreamble());
}
The docs (https://docs.microsoft.com/en-us/dotnet/api/system.text.encoding.getpreamble?view=netcore-3.1) says:
When overridden in a derived class, returns a sequence of bytes that specifies the encoding used.
Looking in specifications for UTF-8 in particular, it's actually not required (See D95 under 3.10 Unicode Encoding Schemes).
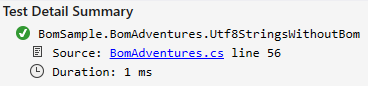
Can we get rid of it?
Yes, just don't use Encoding.UTF8 but instead create an instance of it and define that it should not include the indicator: new UTF8Encoding(false)
[Fact]
public void Utf8StringsWithoutBom()
{
var initial = "Hello world!";
using var ms = new MemoryStream();
using var writer = new StreamWriter(ms, new UTF8Encoding(false));
writer.Write(initial);
writer.Flush();
Assert.Equal(
initial,
Encoding.UTF8.GetString(ms.ToArray()));
}
Great! But then I don't really need a Stream and a StreamWriter? I can just use an encoding instance that excludes the preamble. Right?
[Fact]
public void Outsmarted()
{
var initial = "Hello world!";
var encWithBom = new UTF8Encoding(true);
var encWithoutBom = new UTF8Encoding(false);
var rWithBome = encWithBom.GetBytes(initial);
var rWithoutBom = encWithoutBom.GetBytes(initial);
Assert.NotEqual(
rWithBome,
rWithoutBom);
}
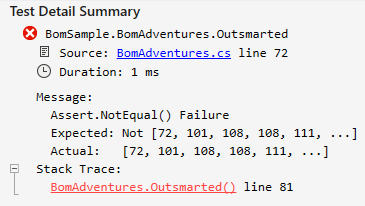
No, it's the StreamWriter that makes use of the Preamble for the encoding. And when creating an Encoding instance with false, it just makes the Preamble consist of an empty array of bytes.
That's all for this post. Hope I clarified something.
Cheers,
//Daniel